Last month HPE released VM Essentials 8.0.8 (given that I’ve been lazy over the summer, 8.0.9 is already available however as I write this) with built in support for migrating VMs from VMware to VME! One of the prerequisites for a successful migration is to inject the Virtio drivers in the VMware VM before starting the migration process. This is not just as simple as mounting the virtio-win-0.1.271 iso image in the VM and double clicking the virtio-win-gt-x64.msi to install it. You actually need to inject the drivers offline to properly accomplish this. And I’m going to show you here how to do that.
And as always before I begin:
Use any tips, tricks, or scripts I post at your own risk.
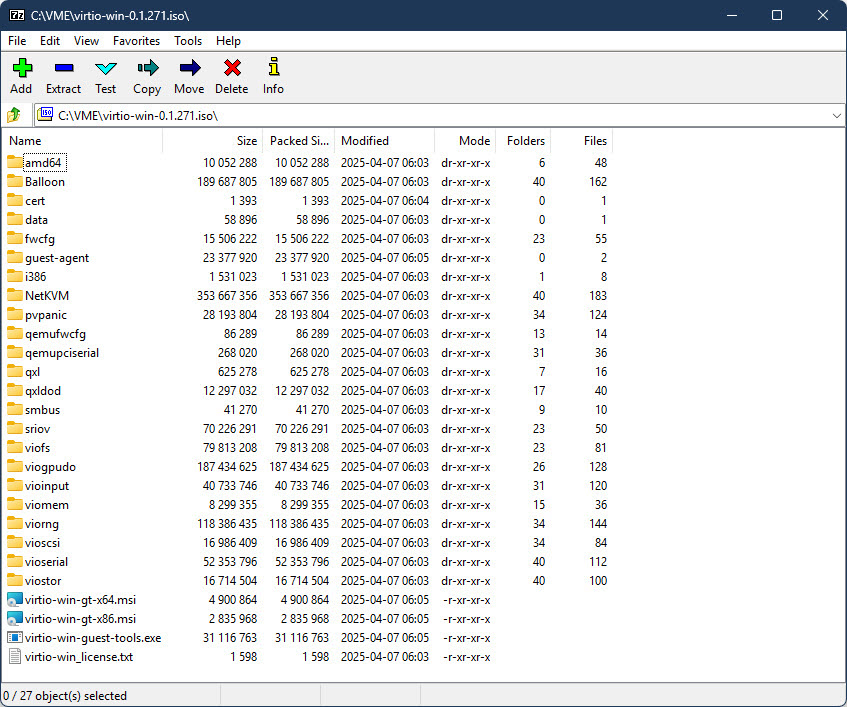
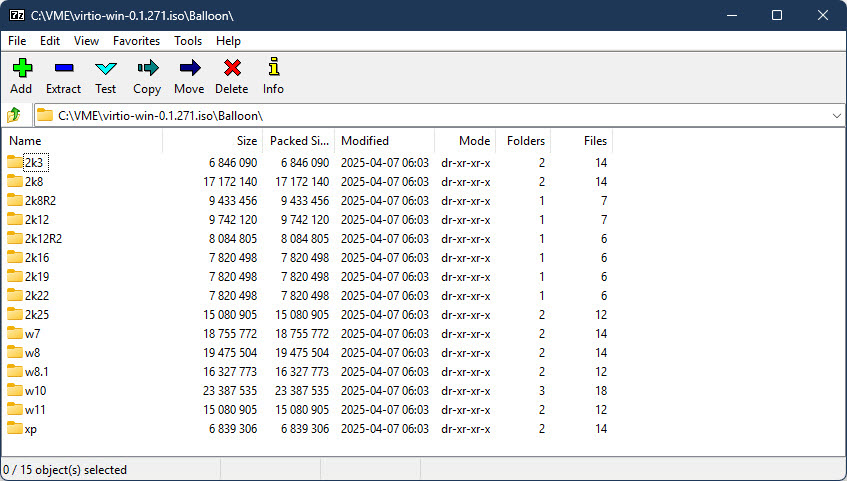
First you will want to extract the .iso image somewhere (I will be using C:\VME\virtio-win-0.1.271 here) with 7-Zip (I am going to assume you already have this .iso downloaded, if not you can find the latest version here). If you look at the contents of the .iso, you’ll find it includes drivers for many Windows OS versions including XP, W7, W8, W10, W11, plus all the server versions from 2003 to 2025.
If you are going to migrate a Windows Server 2022 VM (which is what I’m using as my OS for this post), you probably don’t want to inject the drivers for Windows XP! Now if you are energetic, you could just go manually delete all those OS folders in each driver class, or manually just pick out the drivers you want. I’m not energetic however, and I prefer to work smarter not harder (some might call it lazier though) so I use PowerShell to only give me the drivers I actually need.
Open a PowerShell prompt and paste the following commands:
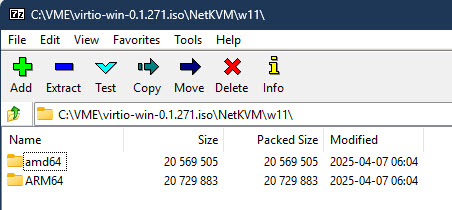
In the example above, Get-ChildItem will go through every top level folder inside of C:\VME\virtio-win-0.1.271 and delete any folder not named 2k22, leaving you with just the drivers for Windows Server 2022. I then like to rename C:\VME\virtio-win-0.1.271 to WIN2022_VIRTIO_DRIVERS (just makes it easier to differentiate for the OS, obviously I replace the Windows version as required in the folder name). As I am constantly building new images and will have a multitude of different OSes for migration, I went ahead and repeated the above steps until I had separate folders for W10, W11, W2016, W2019, W2022, and W2025. One thing to note is that for W11, the drivers are further divided into AMD64 and ARM64 folders under the W11 folder. This is where I became lazy and just manually deleted the ARM64 folders as I don’t expect to ever need them and I only wanted the AMD64 drivers for W11.
At this point, I recommend you go into the WIN2022_VIRTIO_DRIVERS folder and removed the x86 .msi file and also manually removed the i386 folder out of the root (it has W10 x86 drivers in it). And remove the i386 .msi in the guest-agent folder (you aren’t going to need these unless you are running a 32 bit Windows instance).
Since you are going to be copying WIN2022_VIRTIO_DRIVERS to every Windows 2022 Server VM you are going to migrate I also recommend you drop a copy of the PowerShell script to remove VMware Tools into this folder too, which you will run after the migration process. Here’s a link to the script I have been using to remove VMware Tools after migration: https://gist.github.com/broestls/f872872a00acee2fca02017160840624 (thank you Sean Broestl for creating this script)
Now copy WIN2022_VIRTIO_DRIVERS to C:\ in the Windows 2022 Server VM that you want to migrate to VME.
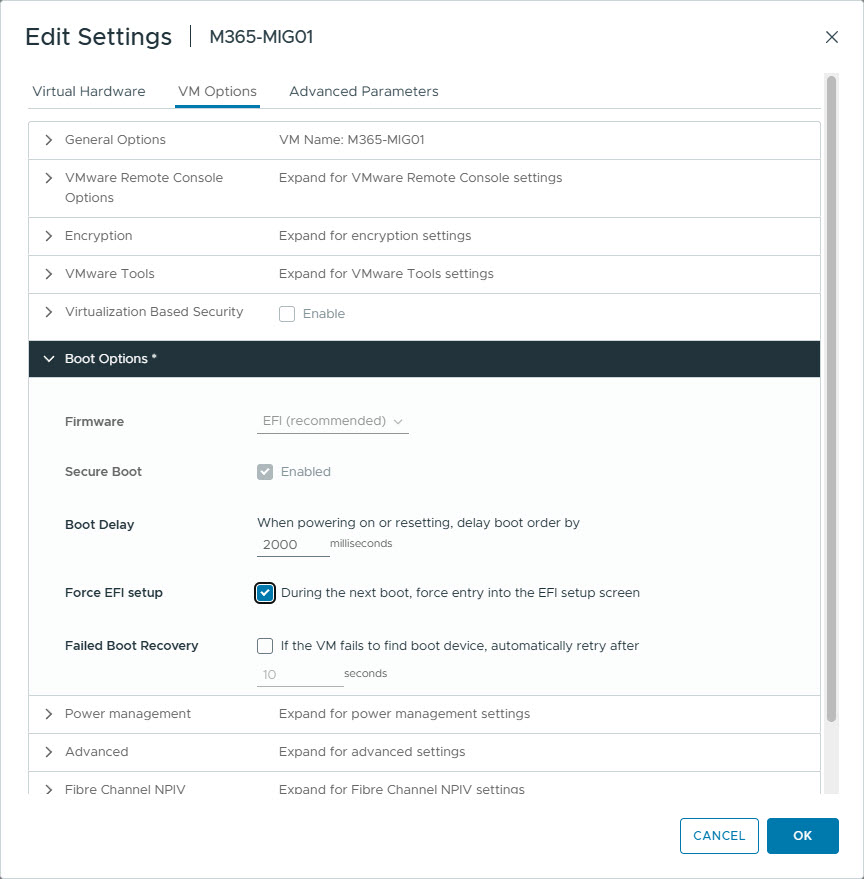
Connect to the VMware Remote Console of that VM and attach the Windows Server 2022 .iso to it. Now edit the VM to force it to boot to UEFI setup (so you can select the .iso to boot from), and reboot the VM.
Once at the UEFI boot menu, select the CD drive and wait for the Windows 2022 Server setup to start.
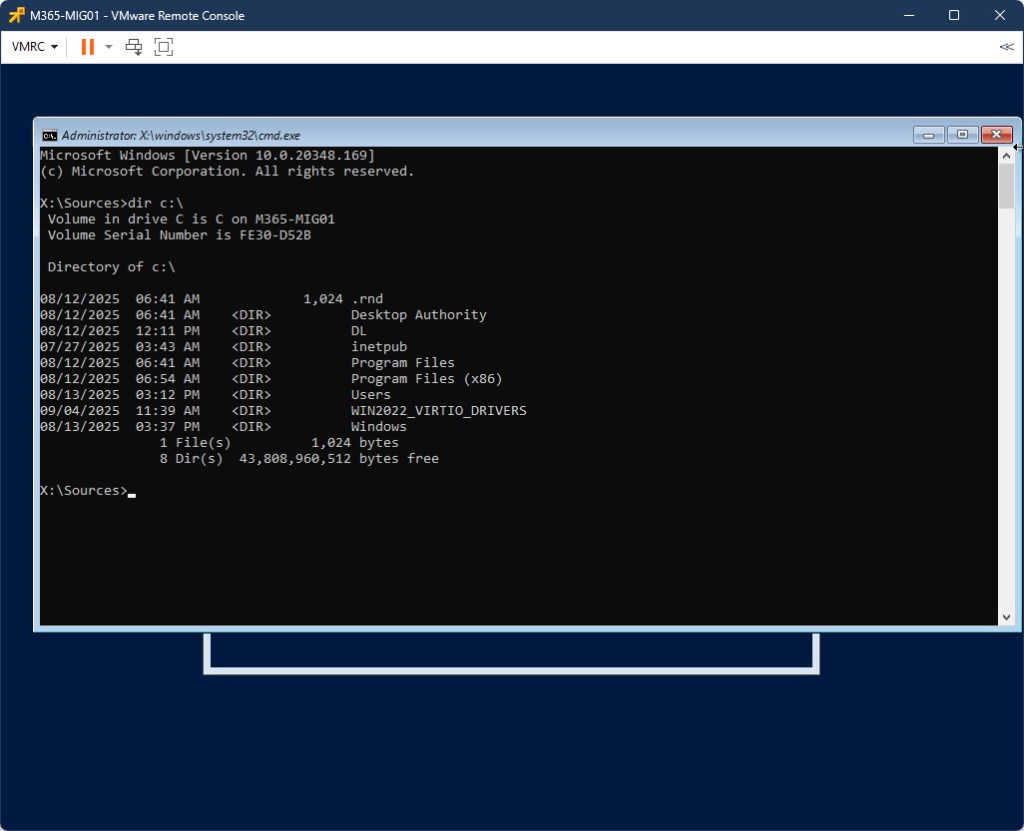
Once at the Setup Welcome screen, and within the VMware Remote Console, press SHIFT + F10 to open a command prompt and verify you can see the C: drive (including the WIN2022_VIRTIO_DRIVERS folder). If necessary scroll through all the drive letters until you find it and substitute C: for that drive letter for the next step. If you do not see your drive, then you probably need to inject the VMware SCSI drivers into your .iso image (which is a totally different blog post).
Now inject the drivers into C:\Windows using the following command:
You can safely ignore any “Error 50” messages (if you see any) – it’s not relevant to this process. Once the drivers have been added, reboot the VM with the following command:
wpeutil reboot
Once back in Windows, install C:\WIN2022_VIRTIO_DRIVERS\virtio-win-gt-x64.msi and reboot again.
Do not bother running C:\WIN2022_VIRTIO_DRIVERS\virtio-win-guest-tools.exe yet – it will fail to install because the hypervisor is still VMware.
Make sure you disconnect the .iso image from the VM before continuing. At this point – your VM is ready for migration. I will be covering the actual migration process in a different post, however the follow up steps related to this post are below.
Once you have migrated your virtual machine from VMware to VME, log back into the VM. VMware Tools will mostly crash on login. Ignore this for a moment and run C:\WIN2022_VIRTIO_DRIVERS\virtio-win-guest-tools.exe. Once that is done, open PowerShell and run C:\WIN2022_VIRTIO_DRIVERS\Remove_VMwareTools.ps1. Reboot when the script finishes, and you should now have a working VM migrated from VMware to VME!
I recently migrated a virtual machine from VMware to HPE VM Essentials (VME) and discovered that the migration process created the new VME VM as UEFI based when it was actually supposed to be BIOS based, and a result, the OS would not boot under VME. Unfortunately, at the time of this writing, VME Manager (8.0.9) does not provide any means to accomplish this via the WebUI in Manager. This meant I needed to edit the VM definition and change it. While it is possible to accomplish, this is very unsupported by the VME team as you need to manually edit the .xml definition file (which they do not support). That said, I’m guessing if you are hear reading this, you don’t care and just want your VM to boot… So lets get to it!
Please note: Use any tips, tricks, or scripts I post at your own risk.
From the HVM host console that hosts the VM, ensure the VM is shut off and then run:
virsh edit VMNAME
(Note – VMNAME is case-sensitive throughout these instructions)
Approximately 24 lines down, you will see the following two sections for <os> and <features> (if the VM is UEFI based):
(Note – I apologize because the xml formatting above is not correct – I’ve struggled the last hour with WordPress.com’s stupid editor to fix this and I give up – it’s a piece of shit, and they want to charge me a bunch more money to get a plugin to fix this, which I refuse to do).
To convert this VM to BIOS based, delete the following two lines from <os>:
To delete lines in virsh edit, you can just put your cursor on the line to delete and press the letter d twice quickly. To save the configuration in virsh, press Esc, : (colon), and enter wq! and hit enter. Assuming you did not mess the editing up, the file will save. If you see “Failed. Try again? [y,n,i,f,?]”, then press N to completely discard the changes you made and start again. Pressing Y will take you back to the configuration with your changes still present, but unless you know exactly what you did wrong, I do not recommend doing this.
Remove the now unrquired NVRAM file: rm /var/lib/libvirt/qemu/nvram/VMNAME_VARS.fd
Now you should be able to start your VM (virsh start VMNAME)
If need to convert from BIOS to UEFI, use the same method, except in virsh edit, press the letter i (eye) to enter insert mode and update the <os> and <features> sections to mirror above. Take note that you need to update the NVRAM file name, and then back in the console will you need to:
I recently had a customer sign a HPE GreenLake dHCI contract that included a new Nimble AF40 to replace a 4 year old AF20Q, and we completed the migration this past week. As a MSP, a critical part of the deployment services that we provide our clients includes the sanitizing (or secure wiping) of any products we replace, and this AF20Q was no exception, other than it’s the first 5th generation Nimble we’ve decommissioned. HPE does provide a KB article in Infosight on the necessary steps (search for “KB-000361 Array Sanitization”). And while it is a good guide, it doesn’t totally cover everything you should know to be prepared for prior to starting this process. I should also note, that if you run this sanitization process, when you are done the Nimble becomes nothing more than a boat anchor as it will not have any sort of OS on it to boot from. If you plan to repurpose or reuse it after sanitizing, you will need to reinstall the Nimble OS from two USB keys that you can obtain from Nimble Support. I’d like to share my experiences in this process in the hopes that it will save someone else a headache (both literally and figuratively).
If your Nimble is running an OS version earlier than 5.0.3.0, then these instructions are not for you! You will need to contact Nimble support to obtain two bootable USB keys with the sanitization process on them. If your Nimble is running OS 5.0.3.0 or newer, then you should be good to go with these steps as I’ve written them out.
And as always before I begin:
Use any tips, tricks, or scripts I post at your own risk.
We’ll start with the obvious. Make sure the array your are sanitizing is the correct array, that it’s had all the hosts disconnected from it, and that it has all the volumes / data removed from it in the Nimble’s management console. And of course, ensure the customer actually want’s it sanitized!
In my case, after completing the migration from the AF20Q to the customer’s new AF40, I removed the array from the customer’s rack, brought it back to my office and set it on my workbench, which is 6 feet away from my desk. This was my first mistake – once you boot the unit to begin sanitization, the fans kick up to high, and they don’t stop! This AF20Q had 12 x 960GB SSDs in it, and the sanitization process took about 8 ¼ hours from power on to power off. With the fans running at high! Needless to say, we found a way to move this unit into another room without powering it down (not recommended, but I had already started the sanitization process and couldn’t stop) and without unplugging a single cable or moving my notebook off the top of it! So if you have a Nimble to sanitize, think very carefully about where it is going to be sitting and the prolonged noise levels that are going to occur during the sanitization process!
Next, when I talked to Nimble support prior to starting the sanitizing, they warned me not to close the serial console sessions to the array once I start the process until it ends, otherwise you’ll have no way to monitor the process (and you’ll never actually know if it completed or not). I would strongly recommend you utilize a dedicated notebook for the task and disable all power management, screensavers, lock screens, and obviously plug it into power with its power brick.
The picture below is after I had finished because as you can see the array has no power cables plugged in and my notebook is powered off.
You should find attached to the back of the Nimble a pair of male DB9 to 3.5mm plug serial adapters (the 3.5mm plug looks like wired headphone jack). You’ll need these, along with two USB to Serial (DB9 – male) adapters, and two DB9 (female / female) serial cables. Plug both USB to Serial adapters into the notebook, and open Windows’s Device Manager to determine the com port numbers associated with each. Plug the other end of the USB to Serial adapter into the DB9 f/f cable and the other end of the DB9 f/f cable into the DB9 to 3.5mm serial adapter. The 3.5mm plug goes into the back of each controller.
With the Nimble still booted up and running, open Putty, and create a serial connection (115200, 8, N, 1) using the correct com port to Controller A. Then open Putty again and create a second connection using the correct com port to Controller B. When you hit enter in each Putty session, you should get a login prompt from the array. Don’t bother trying to login though (it wouldn’t accept the array’s admin credentials when I tried it). All you care about at this time is that you have connectivity via the serial console and can see the console output and that it responded to the keyboard input. The reason you are doing this with the array still booted and running is to verify you can actually see the serial console output via your serial adapter setup – my initial attempt didn’t give me console output and I had to go find a different serial cable. Had I not tested this in advanced, I probably would have gotten impatient and started messing with the settings and stuff before the serial console started outputting any text during the boot process and I would have missed it.
Now you need the Sanitization key (password). For this – you need to call Nimble Support (1-877-364-6253 if you are North American based) and they will generate a Sanitization key which they will email to you. Support told me the key is valid for 24 hours, although KB-000361 says it’s closer to 48 hours – either way, once you have the key, you are on a clock to start.
**Note – I do not know if the array must have a valid support contract on it for them to give you a key – this one still had a contract on it.**
Once you have the key and are ready, open Putty and make your two separate serial connections. I strongly recommend you arrange the two sessions on your screen so they are literally side by side, top to bottom (see picture further below), because you are going to need to be able to see the output of each simultaneously, and you are going to need to interact with both side by side simultaneously (trust me – you do not want to be alt-tabbing trying to find these sessions in the 3 seconds you have to make the correct selection in each – close everything else up except these two sessions!). Open a 3rd Putty session (it can be over top your two serial connections for now though) and this time SSH the management IP of the array and login as admin.
You are now going to reboot the entire array (so both controllers), **AND** (this is important), you must be ready to jump from one serial console to the other at almost the same time to select the correct boot option once it reboots (so get your coffee and use the washroom if you need before you reboot the array instead of thinking you can do so while it’s restarting)!
In order to reboot the array, you need to know the array’s name. To find this, in the SSH session (logged in as the Nimble admin user account) type:
array --list
Then, to reboot the array, you are going to type:
reboot --array array_name
Answer the confirmation for reboot, and after a few seconds, your SSH session will terminate. Close this terminated SSH Putty window and switch to your two Putty serial console sessions (again, they should now be side by side on your screen as shown below). You probably won’t see any activity at all for what seems like 2 or 3 minutes in these sessions. Then suddenly in both sessions (one may be slightly slower than the other – in my case Controller A was about ½ second behind Controller B in all these steps) you’ll see the “Intel® iSCSI Remote Boot” prompt appear for 2 or 3 seconds, and the screen will clear and a few seconds later you’ll see an Intel BIOS screen with [ENTER], [F2], [F6], [F12] options at the bottom of the text.
Get prepared to act fast! A few seconds later this too will disappear and you’ll see a normal grub boot loader page appear with 3 boot options. In the Putty session this appears in first, hit the down arrow twice to move to the 3rd option – “Nimble Array Appliance Sanitization Boot” and hit enter (to select it), then very quickly move to the other Putty serial session and do the same thing. Your total window of opportunity for this is about 3 seconds for both Putty sessions combined – if you miss it (on either controller), immediately pull the power cables from the array, wait 15s, and then plug them in and try again.
So to be perfectly clear – you must boot both controllers with the grub menu option of “Nimble Array Appliance Sanitization Boot”.
And sorry – but I didn’t actually get a picture of that screen, but here’s what it looks like just prior to the grub boot menu opening – as I mentioned Controller A was lagging about ½ second behind Controller B, so that is why the Putty session for COM4 is mostly empty – it populated and looked just like COM5 as I finished the screenshot.
After a minute or two, you’ll find yourself with two Putty serial console sessions full of yellow text. Eventually the output will show you the number of HDDs and SSDs detected in the system, along with an estimate of how long it will take to complete the sanitization (in my case, it predicted approximately 10 hours for 0 HDDs and 12 SSDs, but it really took about 8hr to complete based on the time stamps in my screenshots). Verify these drive count numbers match what you are expecting. If your drive count is what you expect it to be then continue on, otherwise you’ll need to troubleshoot why you aren’t seeing all the drives (perhaps you forgot to power on the expansion shelf first or something if you don’t see what you are expecting). It will also show you the Nimble serial number, the current time (in UTC), and be prompting you for the Sanitization Key.
Working in the Putty serial console session for Controller A (the serial console output refers to this as Controller 0), copy and paste the Sanitization Key into the session from the email you received from Nimble Support. Next you’ll be prompted for the type of sanitization you wish to perform. Your options are:
1.) All Drives and NVDIMM 2.) NVDIMM Only 3.) Drives Only 4.) Quit
**WARNING – There is no going back and no yes/no confirmation when you select one of these options, so make sure you are fully certain you are really ready to destroy this Nimble.**
Select option 1 and the secure wipe / sanitization process immediately starts.
You’ll first see the screen scroll with the NVRAM being zero’d out. This happens pretty much instantaneously. Next, the array will begin to write to all the drives. It does this in 4 different phases, and those phases differ depending on whether the drive is a HDD or SSD. For each hard drive, it writes all zeros to the drive, then it writes all ones to the drive, then it writes a random pattern, and then finally it verifies the random pattern. For each SSD, it writes a random pattern, then verifies the random pattern, then it writes another random pattern, which it then verifies again.
The only time your serial console will show activity is at the beginning of each new phase of writing / verifying, or when the sanitization is complete. This is why you don’t want to disconnect /close your Putty serial console sessions, because otherwise you will not be able to determine what phase you are in or if the process has completed.
Once the secure wipe completes on all the drives, you’ll see a pass/fail result for each drive, along with a statement that the Array Sanitization has completed.
Congratulations – you now have a new boat anchor (or a completely sanitized array if you want to look at it that way too)! You can now pull the power cables from the array and proceed to safely dispose of the asset in an environmental friendly way.
But what if you want to repurpose this array now? That blog post is for another day, but will be coming soon. Stay tuned!
This morning was vCenter update day for me. I had 15 customer vCenter instances that all needed upgraded from 7.0.3.01000 to 7.0.3.01100, so I grabbed a cup of coffee and got started. 14 of the 15 completed with out a hitch, but there is always one! This one vCenter server failed to install the patch, leaving me with a dead vCenter. And this particular vCenter is residing on an HPE Simplivity cluster.
In case you didn’t know, Simplivity has it’s own built in backup and restore mechanism, which is generally accessed via the vCenter client. Which is cool, until your vCenter is dead, and you need to restore your vCenter from those backups, which is done via vCenter (that same dead vCenter you are attempting to restore). Then what do you do? HPE’s documentation on this isn’t super clear. I’d been down this same road earlier this year, so I had already trudged through the framework of what to do once, but I actually hadn’t written down. So this time – not only am I documenting it, I’m sharing it with you!
And as always before I begin:
Use any tips, tricks, or scripts I post at your own risk.
Open Putty and ssh one of the OmniStackVC VMs.
Login as svtcli / yourpassword(this is your emergency password)
Find the available backups: svt-backup-show --emergency
The first column shows the Datastore name. The second column is the VM name. The third column is the backup name and will generally correspond to the backup time. It’s possible to do more granular searches with svt-backup-show. Use --help to get the parameters if you need to narrow down the results.
If the VM has been deleted, then it’s name will show as “VMNAME [Deleted] YYYY-MM-DDTHH:MM:SS+OFFSET” in this list (i.e. “VCENTER01 [DELETED 2022-12-10T13:20:34+0000]” in my example below)
**Note** Your text may be wrapped in Putty – I recommend copying and pasting the text out of Putty into Notepad++ or some other editor for easier reading.
To restore the VM, you’ll need to know the Datastore, the Object, and Backup Name (which is the time of the backup) you are restoring. The syntax for a restore is this:
So in my case, it was: svt-backup-restore --datastore “SVT-DS02” --vm “VCENTER01 [DELETED 2022-12-10T13:20:34+0000]” --backup “2022-12-10T07:00:00-04:00” --emergency –force
If everything worked correctly, you should see a Task Complete. The VM will then be restored into a new folder on the original datastore.
**Note** It may take a minute or two before the restored VM actually appears on the datastore. Be patient! If you simply hit the up arrow and hit enter again to run the restore again, you’ll end up with another copy!
If your original VM has been deleted, then you can safely rename this folder as required to match the original VM’s name. I’m taking these screenshots after the fact, so the existing VCENTER01 shown below is the one I restored earlier this morning (and is now back into production) which inspired this writing – the VCENTER01-restored-blahblahblah is the one I just restored in the screenshots above for my documentation.
Now you can log into the WebUI of one of your ESXi nodes as root, register the recovered vCenter, and power it on. To register the VM, right click Virtual Machines, select “Create/Register VM”, select “register an existing Virtual Machine”, navigate to the datastore and select the restored .vmx file.
**Note** I’m not particularly happy with the editor in WordPress anymore… If anyone knows how I can write these posts in Outlook or Word and then copy and paste (including the formatting) into WordPress, please let me now.
Recently, I had a customer go through a merger, and they inherited another StoreOnce located at a remote site. We made the decision to enable Catalyst copy from the customer’s existing StoreOnce to the inherited StoreOnce to enhance the customers backup and recovery strategy. The only issue was the size of the existing StoreOnce Catalyst store was larger than the available capacity on the inherited StoreOnce, which already had the capacity expansion licensed and installed.
Upon further investigation I discovered that the customer’s Catalyst store had several thousand orphaned Veeam backups from over the years that were no longer present in the VBR database, nor where they picked up by Veeam when rescanning the repository. Deleting these orphaned Veeam files would easily free up enough space in the source Catalyst store to match what was available in the in inherited StoreOnce. All I needed to do was delete these orphaned files!
This however was much easier to say than to do. Because Veeam wasn’t detecting them, I couldn’t use the VBR interface to just select them and delete them from disk. The StoreOnce 4.x WebUI includes the option to list the items in the Catalyst store, and delete them. Unfortunately, it only allows you to select one item at a time, then click delete, and then click through an “are you sure” warning. All told, it probably takes about 8 to 11 seconds per item to delete it, then you need to navigate through the items list again to find the next aged item and repeat this process. This is fine if you only have a handful of items you need to delete. I had somewhere beyond 5800 items to cleanup!
I recalled that HPE offers a tool called “HPE StoreOnce Catalyst Copy Utility”. It is specifically designed to be used to copy backup items to alternate StoreOnce appliances for safekeeping, delete backups that are obsolete or orphaned, and synchronize backup copies between a primary backup target and a disaster recovery site. It can be downloaded from the HPE Software Center (https://myenterpriselicense.hpe.com). What I found out though is the documentation with regards creating the credential file is a bit sparse, so I’m going to take the time explain how to actually use the tool here.
And as always before I begin:
Use any tips, tricks, or scripts I post at your own risk.
Once you have downloaded the tool from the HPE Software Center, run the installer and accept all the defaults. If you are on a Windows machine, this means it’s going to install to C:\Program Files\HPE\StoreOnce\isvsupport\HPE-Catalyst-CATTOOLS
The HPE StoreOnce Catalyst Copy Utility is strictly a console based app – there is no GUI at all. To get started, open an Administrative Command Prompt and navigate to C:\Program Files\HPE\StoreOnce\isvsupport\HPE-Catalyst-CATTOOLS\bin
The first thing you need to do is create an encrypted password file for your Catalyst store. To do this, you run:
Note – the UserName is the username with permissions to the Catalyst Store, which may or may not be the same as the Admin password to the StoreOnce (in fact, from a security perspective, it should be totally different!). If you copy and pasted these command lines, take note that your browser may replace the double dash with a single dash causing the commands to fail.
(You’ll also note that some of my screenshots are blurred and some are not… I got side tracked in the middle of writing this and became lazy since there really isn’t anything here that is secret anyways).
Now that we have our password, lets make sure can connect to the Catalyst Store. To do this, run:
You should get a summary back similar to below that shows the current Catalyst Copy Jobs status.
Back in the WebUI, I’ve filtered by “create date” to find those really old orphaned backups. In my example here, I’m going to remove all the files created prior to May 24 (which is 5 files in this example – and will also break the Veeam backup chain for a couple of them – just something to keep in mind!)
To delete these files with HPE StoreOnce Catalyst Copy Utility, the syntax is:
As you can see, the HPE StoreOnce Catalyst Copy Utility has removed the 5 files older than May 24, 2020. It took only a few seconds in total.
And these deletions are now reflected in the WebUI once I refresh it.
For a full list of the options, advanced filters, and settings related to the HPE StoreOnce Catalyst Copy Utility, be sure to download the user guide from the same page you downloaded the utility from at the HPE Software Center.
And the 5800+ items I had to purge? It was around 294 TiB of capacity and it took a little under 2 hours to complete with this method. The StoreOnce Housekeeping Space Reclamation process is working away at reclaiming all that capacity now.
It’s no secret that I exclusively utilize HPE’s oem’d Marvell Ethernet and FC adapters in not only my own servers, but all of my customers servers too. For the most part, they work great, they are feature rich compared to the competition, and lets face it, they are cost effective. The downside is that the firmware updating process provided by HPE is not overly robust, and has more than once left me with a bricked adapter. Once bricked, the adapter still appears in the ILO and server inventory, but doesn’t show any ports, MAC addresses, etc. So then I have to wait for HPE PointNext to dispatch a field tech to replace the bricked card because apparently they do not know how to fix it.
While troubleshooting another issue a while back with both the HPE ILO and Marvell Ethernet firmware development teams, the topic of bricked, borked, or otherwise dead adapters after failed HPE firmware updates came up. One of the Marvell engineers shared with me how to bring these adapters back to life, and I’m going to re-share that here. It’s a relatively easy process, and saves you from having to call to HPE support and waiting for PointNext to come replace it.
My screenshots below are based on a DL380 Gen9. As near as I can tell, this works on both Intel and AMD based Gen9 and Gen10 servers (I have definitely tested it on DL360 Gen9, DL360 Gen10, DL380 Gen9, DL380 Gen, DL325 Gen10 and DL385 Gen10). So just because the screenshots below may not look exactly like your system, the same basic steps will apply.
And as always before I begin:
Use any tips, tricks, or scripts I post at your own risk.
First, you need to extract the current firmware from the HPE executable with 7-Zip. Ideally you’ll want just the firmware .bin file in it’s own folder.
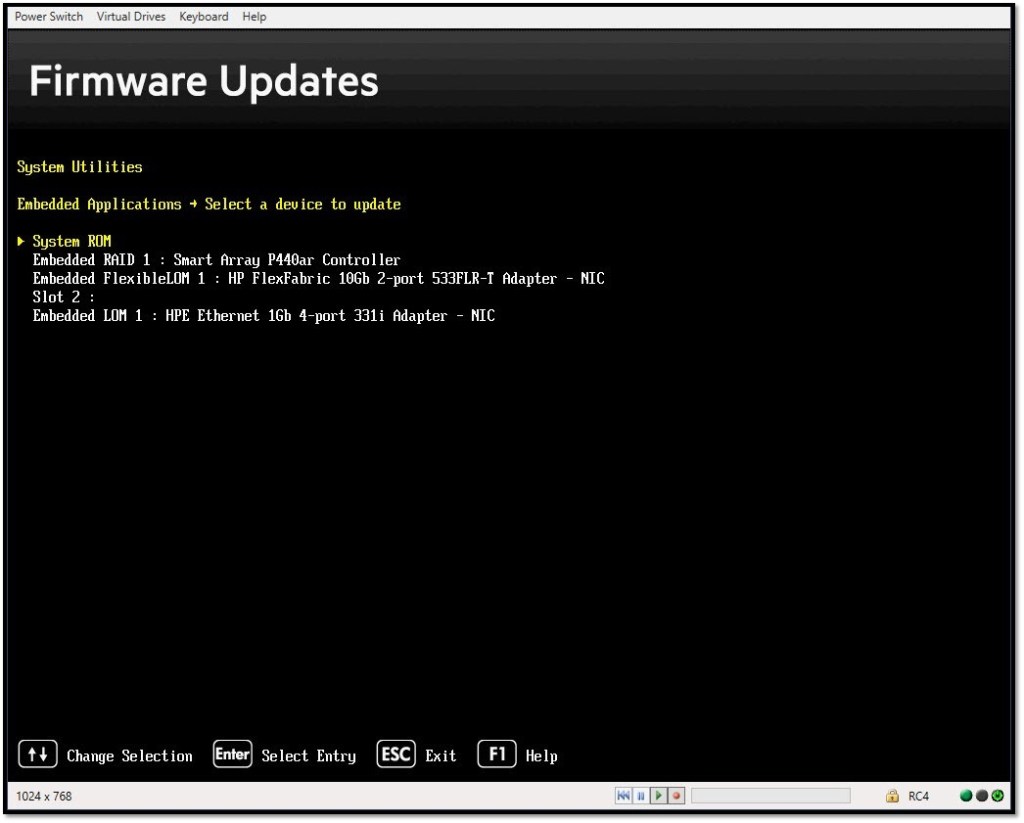
Next open Internet Explorer, log into the ILO and opened the .NET ILO console. Reboot the server to the RBSU and select embedded applications.
From the Virtual Drives drop down menu, select Folder. If you do not see Folder listed there, then you did not use Internet Explorer and / or the .NET ILO console, which is required to be able to mount a folder via the ILO.
Navigated to the folder where the extracted the firmware is and picked the folder that had the .bin file in it.
Select Firmware Update from the list of Embedded Applications, then select the adapter that requires reflashing from the list of devices.
*** Note that depending on the bricked-ness of the adapter – it may not actually appear as it’s real name – but it should be obvious which device it is by process of elimination.
At the Firmware Updates menu, select “Select a firmware file” (**note – this particular 533FLR-T used in these screenshots is not bricked and the “Current Firmware Version” on this 533FLR-T is actually what I’m reflashing with, so the pictures may be differ slightly from what you see on screen)…
When prompted, select “[iLO Folder] iLO Virtual USB 1 : HP iLO Virtual USB Key”.
**Note – the naming of this varies depending on the BIOS version and generation of the Proliant – but the iLO Folder should be obvious in the list.
Select the firmware .bin file from the list presented…
**Note – with Gen10, I’ve noticed that sometimes the file names are truncated to 8.3, so this is why I suggest having only the .bin file in the folder presented via the ILO as it makes it alot easier to pick the right file then!
The new firmware file will load. It generally about 10 to 15s.
Hit Start Firmware Update (as shown in the prior screenshot 3 above)…
The update process will take between 30 and 60s generally.
Once completed, exit back to the RBSU, and cold boot the host via the ILO.
Upon reboot – your Ethernet card will be back alive and ready to go again!
In addition to my previous blog post of upgrading a list of ILO 4’s firmware via PowerShell, I also wrote a similar script for ILO 5. However this script makes use of the iLO Repository and the .fwpkg file type, and does not rely on an IIS server for the ILO to pull the firmware file from. Other than that, it functions very similar to the ILO 4 update script I previously posted.
Below is my PowerShell code. You’ll need to adjust it as required for your own environment. Be sure to update the items in red where required.
And as always: Use any tips, tricks, or scripts I post at your own risk. ### get ILORest here - https://downloads.hpe.com/pub/softlib2/software1/pubsw-windows/p1440367746/v177187/ilorest-3.0.1.0-8.x86_64.msi
Recently, I had to update a bunch of HPE ILO 4s at multiple locations. Most of my managed sites have between 3 and 9 ILOs that need updated when HPE pushes out an ILO firmware update. I could have used ILO federation group firmware update, or the ILO Amplifier Pack to do this, but I’m a fan of scripting things so I just have to RDP a server onsite, open a prompt and paste a few lines of code and let it start doing it’s thing, then RDP the next site and do the same thing. So I built a PowerShell script to download the ILO 4 update, extract the .bin file, copy it an IIS server, and then proceed to upgrade each ILO one a time utilizing the ILO RestAPI.
Below is my PowerShell code. You’ll need to adjust it as required for your own environment. Be sure to update the items in red where required. Keep in mind your IIS server ($iisip) will need to have a mime type associated with bin files for this to work.
And as always:
Use any tips, tricks, or scripts I post at your own risk.
### get ILORest here if you need it - https://downloads.hpe.com/pub/softlib2/software1/pubsw-windows/p1440367746/v177187/ilorest-3.0.1.0-8.x86_64.msi
As I am sure those of you who are heavily involved in architecting Hewlett Packard Enterprise’s infrastructure solutions consisting of servers, storage and networking already know, there was a new HPE Master level certification announced earlier this year. This new certification is the HPE Hybrid IT Master ASE, and it is going to be the pinnacle of all HPE certifications. Many of us that hold Master ASEs in Servers, Storage, and Networking will naturally be looking to obtain this Master ASE certification as well. In some cases, Partner Ready requirements will drive your need to obtain this certification, but I also know that for many of my peers, it’s a matter of pride and desire to achieve this certification. However, it really doesn’t matter the reason that drives you to achieve it, I am writing this article to tell you that achieving this new certification isn’t going to be a walk in the park. HPE opted to take a different path to certification and the traditional testing methods we all know, have tested with before, and are comfortable with have been changed up some for this certification.
By now you are asking yourself how does Dean know about this? Myself, along with several of my peers from around the globe (many of whom you would likely know too) were honored to be invited join the design team for this certification (and some of related electives for the certification). When this certification goes live, it will have been a 15+ month journey for some of us, beginning in August 2018. That journey took us from the initial blueprint of how we wanted to test, to the content of the beta courseware (which was just finished last month), to the certification launch on November 1, 2019. There are hundreds and hundreds of hours involved amongst us in the design of this certification, the courseware, and of course creating the certification exam its self. Along the way, there were many phone calls, Skype meetings, face to face meetings at various HPE facilities, and countless hours of reading (and then revising) the alpha and beta courseware material that makes up both the Hybrid IT ASE and HPE Hybrid IT Master ASE courses and exams. In mid-July (2019) many of us from around the globe gathered in a meeting room at HPE’s campus in Roseville, California to work on the exam creation.
The first thing you’ll notice different is the exam number. Today, we normally all take proctored HPE0-### exams for our certifications. The HPE Hybrid IT Master ASE certification will be an HPE1-### series exam, and will not be delivered by Pearson VUE but rather it will be delivered by PSI. While PSI does have some testing centers, the HPE Hybrid IT Master ASE exam will be an online proctored exam that you will be expected to take at home or at your office – similar to the online proctored HPE0-### exams that are already offered by Pearson VUE.
The second difference you will notice is the length of the exam – you will be given 4 hours to complete it, not the typical 90 or 120 minutes you are used to with the HPE0-### exams (yes – washroom breaks will be allowed).
The third thing you will notice different is both the exam price and the retake policy. The price of the exam will be between $695 and $895 USD depending on your country of residence, which is more than double the price of today’s HPE0-### exams. The retake policy is also different. With HPE0-### exams, you can immediately retake the exam once if you fail it (as long as you have not failed twice in 14 days). With the new HPE1 exam, there will be an automatic 14-day waiting period after each failure before you can rebook for another attempt.
The fourth thing you will notice is the composition of the HPE Hybrid IT Master ASE exam – it will be broken into 3 distinct sections. Questions and answers (similar to today’s exams), a research portion, and a hands on portion (more details on all three of these sections is below). However, for every single item, once you click submit on the answer to the item, there is no going backwards to review or change your answer.
Part one of the exam will consist of a series of Discrete Option Multiple Choice (DOMC) questions. For those of you that have not seen a DOMC exam before, basically you get asked a question, and are presented with a single answer on the screen at a time – to which you either select YES or NO if the answer is correct for the question. Each question may have one or more answers that get presented to the test taker (but still only one answer at a time will appear on the screen). I’ll admit I was very skeptical and concerned when the decision was made to utilize DOMC, but having worked with it for a while now as part of this process, I’m very comfortable with it and I am no longer concerned it will affect your chances of passing or failing.
Part two of the exam will probably start to take some of you out of your comfort zone. You’ll be given a series of scenarios that you will need to answer questions about. Some scenarios may build on previous scenarios you were given as well. You’ll RDP a remote environment, and be required to observe many items in that environment to answer questions about accurately building a solution that properly integrates with that existing environment. Nothing is off the table here from Synergy frames to storage systems and network switches. Almost all the Hybrid IT portfolio and their respective management GUIs or CLIs are present here – you’ll need to know where to look to determine if the answer presented to you (via DOMC) is correct. This is no different from what you’d need to do if you were designing an upgrade for one of your customers. A simple example is “Your customer wants to do this with their existing environment, do you need to add this particular item to your solution to accomplish this? YES or NO”.
If part two got you out of your comfort zone, then part three is going to really take you far out of your comfort zone… In part two, you are simply reviewing the exam’s hardware infrastructure and environment, but in part three, you are actually modifying the environment – with very real hardware that you are connected to. Think of it as having to perform a demo of a feature or something to one of your customers using their existing equipment.
You know all those hands on labs offered at various HPE conferences that you may have attended in the past, but you’ve skipped to spend extra time at the bar in the evenings? Well those HOL experiences will be very handy here, as it’s very much hands on with the management tools (both GUI and CLI). Everything from configuring, upgrading, or fixing connectivity issues with Synergy, 3Par, Windows, vCenter, and switches (of all types) is covered here – and you may need to use multiple tools from across the portfolio to accomplish your tasks. You may use either the GUI or CLI to accomplish your task (or maybe both), but the task must be 100% correct and completed when you hit the submit button.
You will be provided all the appropriate manuals, CLI guides, and documentation you require to complete the tasks – they will available on the server you will be RDPing into. So it’s opened book so to speak – you’ll have these resources, but only these resources (you won’t be able to search the internet for walkthroughs!). However, if you have to utilize the provided material to look up how to complete every single little step, you’ll quickly run out of time – the documentation is there to provide you a guide, not tell you how to perform (i.e. for the first time in your life) whatever action it is you need to do.
A word of warning though – as this is real hardware, running in a real datacenter, it is possible for you to completely break the testing environment, which will prevent you from completing your assigned task, possibly resulting a score of zero for the task. In the real world, if you mess up and accidently destroy or delete something in your customer’s running environment, you’ll have failed in the customer’s eyes. This is no different – if you break the testing environment here (i.e. maybe you accidentally deleted a volume instead of extending a volume) and are unable to complete the assigned task because of it, then you’ll fail the question.
HPE says this is the first time anyone in the IT certification industry has used real hardware and an automated scoring system in real-time to verify that what you have done is correct. Spelling counts. Exactly correct numbers count (i.e. 100MB vs. 1000MB). If you are asked in a scenario to name something “bigwheel” and you name it “big wheel” with a space (or you typo it as “bigwhel”), then that answer will be marked wrong (although we are told the scoring won’t look at the case sensitivity of the answer, just the spelling, spacing, etc.). So just like in real life – spelling errors and wrong numbers will result in broken configs, or in this case a wrong answer. This is completely automated scoring (don’t worry – it’s been fully vetted by your peers already) – so when you hit that final submit button (and I do believe if memory serves me correctly that you’ll be warned that your answer / task is about to be scored if you hit submit), the testing software instantly runs a series of scripts that interrogates everything that makes up the exam’s hardware environment and looks at the relevant output to determine if you’ve correctly accomplished your assigned tasks. So you’ll know in just a few seconds after hitting that very final submit button if you are the world’s newest HPE Hybrid IT Master ASE or not!
The HPE Hybrid IT Master ASE certification exam is not going to be for the faint of heart. This certification is going to require you to have several years of real world experience and knowledge in HPE compute, storage, and networking. And if you think you are going to be able to rely on a brain dump to pass, think again – DOMC, the scenarios on real hardware, the exam cost, and the retake policy (along with some other things I can’t discuss) are going to put a serious crimp on both the quality and quantity of brain dumps that will be available.
So what are my tips to you for achieving this certification?
Do take the course. Yes it is expensive and time consuming, but it will cover (including hands on labs) the concepts and knowledge you must have (aside from the real world experience you should already have) to pass the certification exam.
Do not wait to take the exam once you have taken the course – take the exam while the course and hands on labs are fresh in your mind.
Be prepared to wait for an exam slot. I think initially it will be hard to schedule an exam due to demand and the limited number of testing slots available per day (given that the exam requires a complete set of real hardware that must be flattened and reset after each exam).
Do not wake up one morning and decide to take this exam in the afternoon “cold” without properly preparing. Many of us do this today at various events we attend (i.e. Aspire, TSS, Discover), and it’s not going to result in an exam pass here. I know of maybe a handful of my peers in the world that maybe could do that without any preparation and have a reasonable chance of passing.
Do read, re-read, and then re-read every single word of every single question on the exam – some of the questions and scenarios are very long with lots of information, and it’s easy to skip over key details, words, or numbers that you will need to accurately answer the question or complete the scenario assignments.
Do not be intimidated by the DOMC format – it’s really not as bad as you may initially fear.
Do take the practice DOMC exam so you have an idea of what to expect on the real exam. You can find a HPE DOMC practice exam (with examples of ASE level server/storage/networking items) at the following link: https://sei.caveon.com/launchpad?exam=try-domc-for-hpe
For those of you planning to try to obtain this certification, before you register for the course, I’d suggest you chat with your regional Partner Enablement Manager to see if there are any promotions running for the course and exam (wink, wink, you may find a pleasant surprise).
I would like to wrap up by offering you the best of luck in obtaining the HPE Hybrid IT Master ASE certification and to remind you:
You will truly need to be a Master of HPE Hybrid IT to become a HPE Hybrid IT Master ASE!
Most of my customer sites consist of one to four HPE Proliant DL3xx servers running VMware ESXi and an additional HPE Proliant DL3xx running Windows 2012 R2 / 2016. HPE offers some great tools for managing their servers, but unfortunately for smaller organizations, most of HPE’s management tools (and I’m looking squarely at you Insight Control and OneView) take more time to setup and get running correctly then the time you’ll save by installing / updating a small handful of servers manually. Therefore, I usually don’t deploy these tools to help install OSes or update firmware at my smaller client sites. I generally just rely on booting the HPE Support Pack for Proliant (SPP) to update firmware, use a USB key with a scripted ESXi install on it for installing ESXi, and utilize WDS to install Windows directly on my Proliants when required.
Prior to HPE Proliant Gen 9 servers, I would PXE boot the Proliant Service Pack using PXELINUX and mount the ISO via NFS. Then along came Gen 9 with UEFI. Unfortunately, PXELINUX suffers from a complete lack of support for UEFI. A couple of times I pestered some of the HPE SPP developers and managers in person while at HPE’s campus in Houston, but they never really showed much interest in explaining or documenting how to get network booting working with the SPP when the server utilized UEFI, so I had pretty much given up on ever getting it to work.
The other day I was playing with the HPE RESTful Interface Tool and decided to try configuring HTTP boot on DL380 Gen10 with the current SPP ISO image (P11740_001_spp-2018.11.0-SPP2018110.2018_1114.38.iso). Much to my surprise, after modifying only a single configuration file on the ISO image, I was able to successfully boot the current SPP ISO image via HTTP and run a full firmware update on the Gen10 I was playing with.
The nice thing about this method is that because it is all done via HTTP, you don’t have to mess with or disable your WDS (Windows Deployment Services) server to add Linux support (which is what the SPP ISO is based on). So this is great news for pure Windows shops! And as a bonus, these steps works with Gen 9 servers too.
So how did I do it? Before I share that, as always:
Use any tips, tricks, or scripts I post at your own risk.
First, you need to slightly modify the SPP ISO image. Copy the original SPP ISO image to your web server (i.e. c:\inetpub\wwwroot).
Open the ISO image with your favorite ISO editor and extract \efi\boot\grub.cfg, then open the grub.cfg with a decent text editor (i.e. Notepad++, but definitely not the built-in Windows Notepad). Scroll down the first menuentry, which will be “Automatic Firmware Update”. Then copy and paste the following just above that menuentry:
So your grub.cfg will look like this when you are done:
Adjust the http address (xxx.xxx.xxx.xxx), path, and ISO image name as required for your network, then save the updated grub.cfg and inject it back into the ISO image, over-writing the existing \efi\boot\grub.cfg, and then save the updated ISO image.
Be sure to add the .ISO mime type to your web server so that the ISO file type can be handled correctly. The command below will work with IIS 8.5 and above to add a new mime type to IIS for .ISO.
C:\Windows\System32\inetsrv\appcmd.exe set config -section:system.webServer/staticContent /+"[fileExtension='iso',mimeType='application/iso']"
Now, you need to install the HPE RESTful Interface Tool on your machine. The current version at the time of this writing is 2.3.4.0. Go to the Hewlett Packard Enterprise Support Center and search for “RESTful Interface Tool for Windows”, then download and install the .msi (there is a Linux version available as well there).
Once the HPE RESTful Interface Tool is installed, run it as an Administrator. Next, you need to connect to your server’s ILO, select the Bios object, set the UrlBootfile Entry and commit the changes.
*** NOTE: Make sure the UrlBootFile entry matches the url of your ISO image that your put on your webserver and specified as the iso1 switch in the grub.cfg entry.
This takes care of the changes you must make to your Proliant server (keep in mind each server that you want to HTTP boot needs to have this this done).
The next time your server boots, the UrlBootFile change will be applied at the end of POST, then server will automatically reboot and start to POST again.
That’s it – your configuration is all done. Now when you reboot your server, if you hit F11 for the Boot Menu, you’ll have an entry for HTTP there – select it.
After maybe 30 to 45 seconds (depending on your network speed – I’m using 10GbE), you’ll see the familiar SPP boot menu, but with an extra entry which is set as the default entry.
Select it, and after about a minute (again – I’m using 10GbE) you’ll see the ISO image get mounted.
If the image fails to mount, verify you are able to download the image you specified as the UrlBootFile from your PC. If that works, then verify that the grub.cfg is correctly updated, with no typos. Also – verify your server has 16GB+ of RAM in it, as the grub entry creates a 10GB RAM disk. You may also need to upgrade the ILO firmware and drivers to current builds (such as 2.61 for ILO4 or 1.39 for ILO5) before using the iLOrest tool.
If you so desire, you could also set the new grub entry to be totally automatic by grabbing the proper switches out of the “Automatic Firmware Update” entry. I suspect it may also be possible to split the ISO and boot one ISO without the packages folder (so it boots quicker) and mount a second the ISO with the packages folders still there to run the upgrades from. Just to be clear, I haven’t tested that yet – it’s just a theory at this point.
I have tested this by HTTP booting over a branch office VPN tunnel which tops out at 100Mbps – it took a while for the image to load (I didn’t time it as I was working on other things at the time), but it did eventually load and it successfully updated the remote server.
When the next Support Pack for Proliant is released, all you need to do is update the grub.cfg with the correct paths and copy the updated ISO to your webserver with the same file name you used here. You shouldn’t need to adjust the UrlBootFile on your servers.



































You must be logged in to post a comment.